With over 11 million users and 30+ million projects, GITHUB is the most popular code versioning tool now. It’s not only used in the public domain to share code with the world but it also used at enterprise level to share code and collaborate with different teams in the organization.
In this blog, I will try to explain how to use GIT ( command line utility) to perform the common operations that a developer might do on a daily basis. All the instructions are for a MAC but should work for other platforms too.
Install Instructions.
-
Download Git from here.Git
-
Installation instructions HERE
-
Once installed, open up a terminal window (MAC/UNIX) or command prompt in Windows and enter the command ‘git’ in window to verify if GIT is installed fine.
Configuration
Git config files are stored in one of the following locations.
.git/config - The .git folder of the a specific repository.
~/.gitconfig - Machine user specific configuration.
/etc/gitconfig - Common configuration for all users.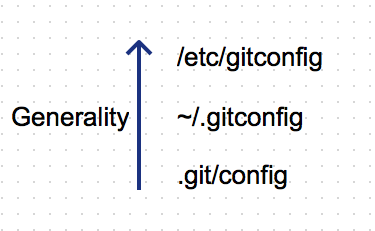 </img>
</img>
Using Git
In the upcoming section I will explain how to use the GIT commands to achieve the following not necessarily in the same order indicated below.
- Creating a new code repository.
- Adding files to the repository.
- Pushing files.
- Making changes to a file and updating the code repository.
- Taking the latest code.
- Cloning a repository.
- Removing files.
- Ignore certain files.
- Resolving code conficts. [ Pending]
- Creating branches. [ Pending]
- Merging branches. [ Pending]
Git In Action
-
First register for a github account here.
-
For the purpose of this tutorial, I will keep the username/password as
1
(gittutorial@gmail.com/gittest) -
Configure GIT on the machine so that it can talk to the GITHUB code repository.Start a terminal and enter the following commands.
root@machmachine:/# git config --global user.name GitTutorial
root@machmachine:/# git config --global user.email gittutorial@gmail.com- Now create a folder
1
mycoderepo
root@machmachine:/# mkdir mycoderepo
root@machmachine:/# cd mycoderepo
root@machmachine:/# echo 'my first file' > myfirstfile.txt- Initialize the current folder as a repository and add the newly created file to be part of the repo.
root@70bb83c437ca:/mycoderepo# git init
Initialized empty Git repository in /mycoderepo/.git/
root@70bb83c437ca:/mycoderepo# git add myfirstfile.txt
root@70bb83c437ca:/mycoderepo# git commit -m 'My first commit'
[master (root-commit) 8333c6b] My first commit
1 file changed, 1 insertion(+)
create mode 100644 myfirstfile.txt
root@70bb83c437ca:/mycoderepo# git status
On branch master
nothing to commit, working directory clean- Create repository. Verfiy email if needed.
root@70bb83c437ca:/mycoderepo# curl -u 'GitTutorial' https://api.github.com/user/repos -d '{"name":"git-tutorial","description":"Repo for git tutorial"}'
Enter host password for user 'GitTutorial':
{
"message": "At least one email address must be verified to do that.",
"documentation_url": "https://help.github.com/articles/adding-an-email-address-to-your-github-account"
}
root@70bb83c437ca:/mycoderepo# curl -u 'GitTutorial' https://api.github.com/user/repos -d '{"name":"git-tutorial","description":"Repo for git tutorial"}'
...
... // Repo will be created and a long list of parameters returned. We are concerned only about the ssh_url param.
...
..
"ssh_url": "git://github.com/GitTutorial/git-tutorial.git",- Defining the remote location where to push the local repository.
root@70bb83c437ca:/mycoderepo# git remote add origin git@github.com:GitTutorial/git-tutorial.git
root@70bb83c437ca:/mycoderepo# git push origin master
The authenticity of host 'github.com (192.30.252.130)' can't be established.
RSA key fingerprint is 16:27:ac:a5:76:28:2d:36:63:1b:56:4d:eb:df:a6:48.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'github.com,192.30.252.130' (RSA) to the list of known hosts.
Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.- Pushing files. You will encounter the permission denied error first time. Create a new SSH key as described here to resolve it.
root@70bb83c437ca:/mycoderepo# git remote add origin git@github.com:GitTutorial/git-tutorial.git
root@70bb83c437ca:/mycoderepo# git push origin master
The authenticity of host 'github.com (192.30.252.130)' can't be established.
RSA key fingerprint is 16:27:ac:a5:76:28:2d:36:63:1b:56:4d:eb:df:a6:48.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'github.com,192.30.252.130' (RSA) to the list of known hosts.
Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.- Once the SSH issue is resolved we can re-try the command to push the code to the ‘master’ branch of the repo.
root@70bb83c437ca:/mycoderepo# git push origin master
Counting objects: 3, done.
Writing objects: 100% (3/3), 232 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To git@github.com:GitTutorial/git-tutorial.git
* [new branch] master -> master
root@70bb83c437ca:/mycoderepo# - Lets add another file and check the status of the repository.
root@70bb83c437ca:/mycoderepo# echo 'my second file' > mysecondfile.txt
root@70bb83c437ca:/mycoderepo# git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
mysecondfile.txt
nothing added to commit but untracked files present (use "git add" to track)
root@70bb83c437ca:/mycoderepo# git add mysecondfile.txt
root@70bb83c437ca:/mycoderepo# git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: mysecondfile.txt- Lets add few more files. Note that we can user wild cards to refer to files.
root@70bb83c437ca:/mycoderepo# echo 'alert("hi")' > alert.js
root@70bb83c437ca:/mycoderepo# echo 'timer()' > timer.js
root@70bb83c437ca:/mycoderepo# git add *.js
root@70bb83c437ca:/mycoderepo# git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: alert.js
new file: mysecondfile.txt
new file: timer.js- Let’s say that we accidentally added ‘timer.js’ to be pushed. If we want to revert this back.
root@70bb83c437ca:/mycoderepo# git rm -f timer.js
rm 'timer.js'
root@70bb83c437ca:/mycoderepo# git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: alert.js
new file: mysecondfile.txt
root@70bb83c437ca:/mycoderepo# - Lets commit and push this to Master branch.
root@70bb83c437ca:/mycoderepo# git commit -m 'adding two files'
[master 03cfada] adding two files
2 files changed, 2 insertions(+)
create mode 100644 alert.js
create mode 100644 mysecondfile.txt
root@70bb83c437ca:/mycoderepo# git push origin master
Counting objects: 5, done.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (4/4), 352 bytes | 0 bytes/s, done.
Total 4 (delta 0), reused 0 (delta 0)
To git@github.com:GitTutorial/git-tutorial.git
8333c6b..03cfada master -> master- Let’s modify the first file and delete the second file from local repo and push the changes out to remote.
root@70bb83c437ca:/ echo 'adding new line to first file' >> myfirstfile.txt
root@70bb83c437ca:/mycoderepo# rm -f alert.js
root@70bb83c437ca:/mycoderepo# git status
On branch master
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: alert.js
modified: myfirstfile.txt
no changes added to commit (use "git add" and/or "git commit -a")
root@70bb83c437ca:/mycoderepo# git add myfirstfile.txt
root@70bb83c437ca:/mycoderepo# git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: myfirstfile.txt
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: alert.js
root@70bb83c437ca:/mycoderepo# git rm alert.js
rm 'alert.js'
root@70bb83c437ca:/mycoderepo# git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
deleted: alert.js
modified: myfirstfile.txt
root@70bb83c437ca:/mycoderepo# git commit -m 'updating and removing files'
[master ec42984] updating and removing files
2 files changed, 1 insertion(+), 2 deletions(-)
delete mode 100644 alert.js
root@70bb83c437ca:/mycoderepo# git push origin master
Counting objects: 5, done.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 318 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To git@github.com:GitTutorial/git-tutorial.git
03cfada..ec42984 master -> master- If you don’t want some files to be reported as part of ‘git status’ command and never want to push it to remote repository then create a `.gitingore’ file with the file patterns that need to be ignored.
root@70bb83c437ca:/mycoderepo# cat .gitignore
*.class
**/target/*.war
/*.jar- If you want to clone the remote repository on a different machine or at a different location.
root@70bb83c437ca:/mycoderepo# git remote show origin
* remote origin
Fetch URL: git@github.com:GitTutorial/git-tutorial.git
Push URL: git@github.com:GitTutorial/git-tutorial.git
HEAD branch: master
Remote branch:
master tracked
Local ref configured for 'git push':
master pushes to master (up to date)
root@70bb83c437ca:/mycoderepo# cd ../mycoderepo-cloned/
root@70bb83c437ca:/mycoderepo-cloned# git clone git@github.com:GitTutorial/git-tutorial.git
Cloning into 'git-tutorial'...
remote: Counting objects: 10, done.
remote: Compressing objects: 100% (5/5), done.
remote: Total 10 (delta 0), reused 10 (delta 0), pack-reused 0
Receiving objects: 100% (10/10), done.
Checking connectivity... done. </img>
</img>
 </img>
</img>
 </img>
</img>
 </img>
</img>
 </img>
</img>
 </img>
</img>
 </img>
</img>