Most of the applications have some sort of badging functionality which is used to display certain counts to the users for CTA (Call To Action).
Once the user has clicked or acknowledged the counter then the value associated with the counter will be reset.
Given a system with large number of users and working off a large data set, it’s not always possible to compute the counter values in real time.
Also, it may not make sense to update multiple records for different users when the counters are acknowledged.
There are three actions associated with the counters
Increment
Decrement - This usually happens when an action is undone or something is deleted.
Reset - When user acknowledges the counter.
All the above actions could happen concurrently and be associated with an user. For this reason, all the operations on the counter needs to be atomic else the counters would be off the correct value.
A common example for the badging/counter feature is the Facebook notification system.
The counters associated with the user are based on the actions performed by other users.
An user can be associated with several other users and many of those other users could be performing the same or different actions at the same time.
Like, there could be 3 people sending the user messages or another 4 people sending friend requests.
</img>
Facebook Notifications
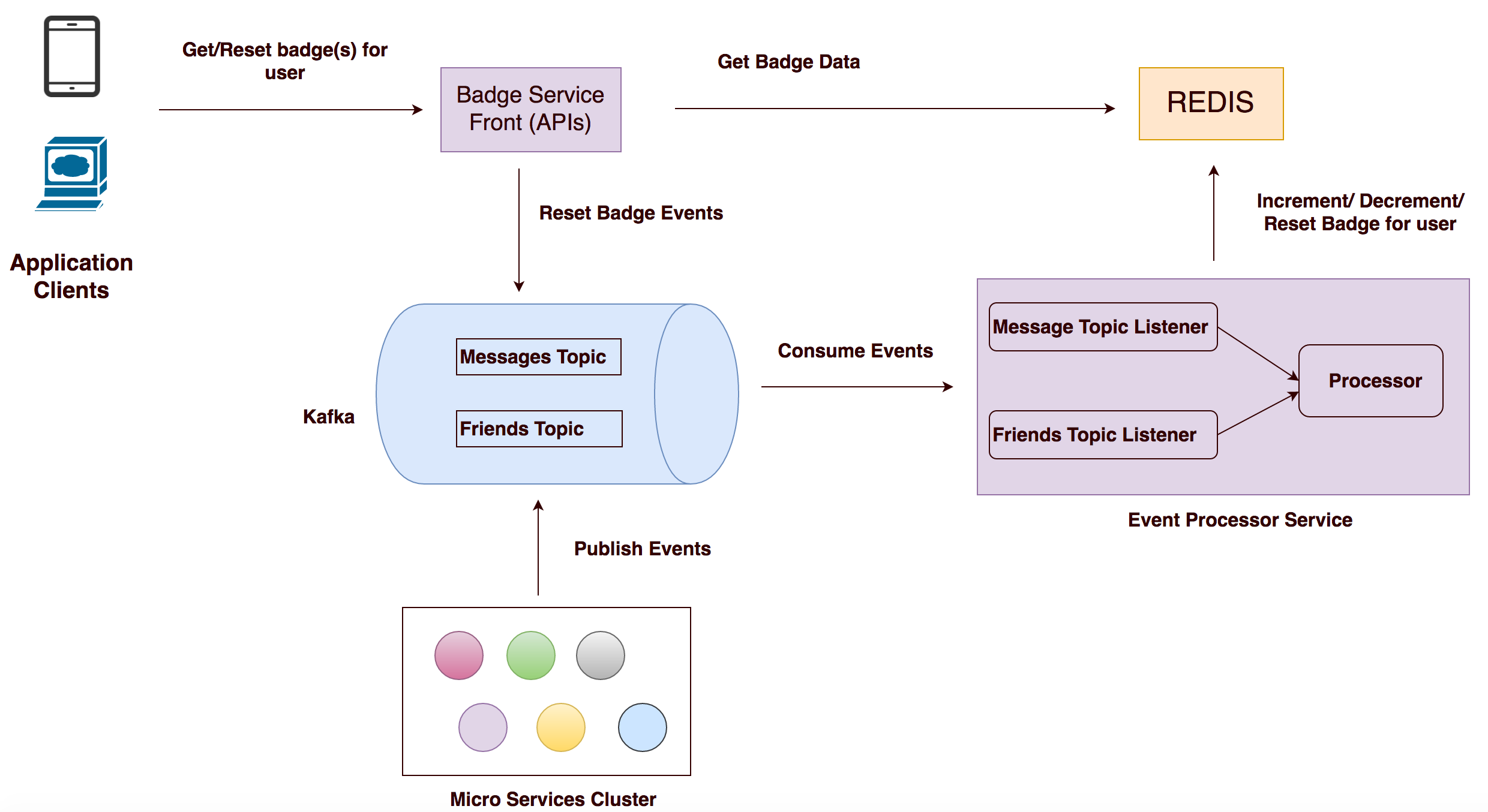
Given the above behavior of the system, the badging system can be architectured as below. The system would be event driven and the counter values eventually consistent.
Each microservice would generate events which gets listened by an events processor service. Based on the data in the event, the processor will update the
value of counters associated with the user.
</img>
Simple Badging/Counter Service Architecture
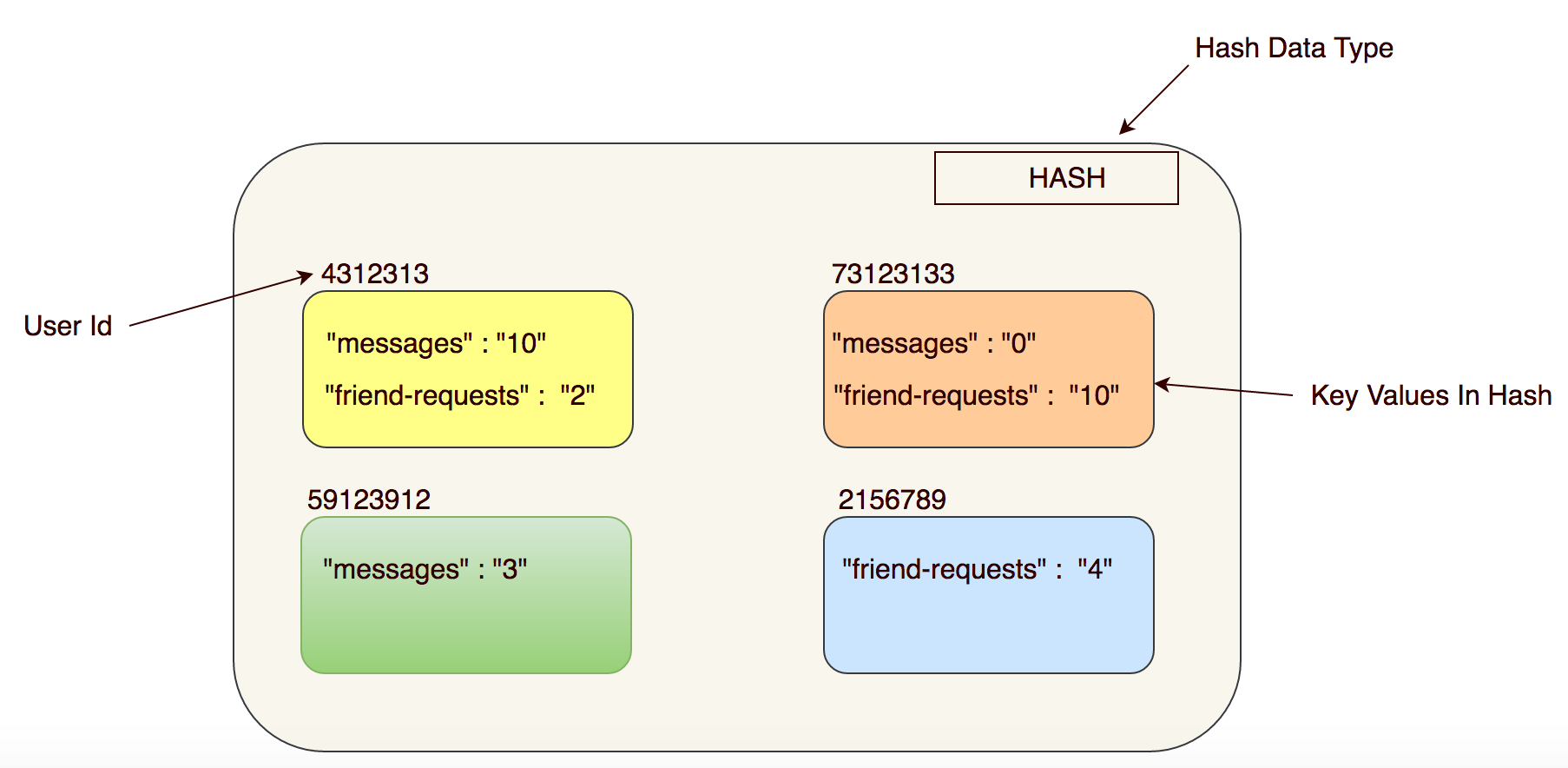
Here is a simple example of the REDIS HASH data structure which can be used to store the counters associated with the user.
Each HASH is associated with a userId and all the counters are tied to the hash as key-value pairs.
Spring Boot Admin is a library which can be added to spring boot application to provide administrative capabilities.
You can look at the github pages of the ‘Spring Boot Admin’ project to see what various feature of the ‘Spring Boot Admin’ libraries are.
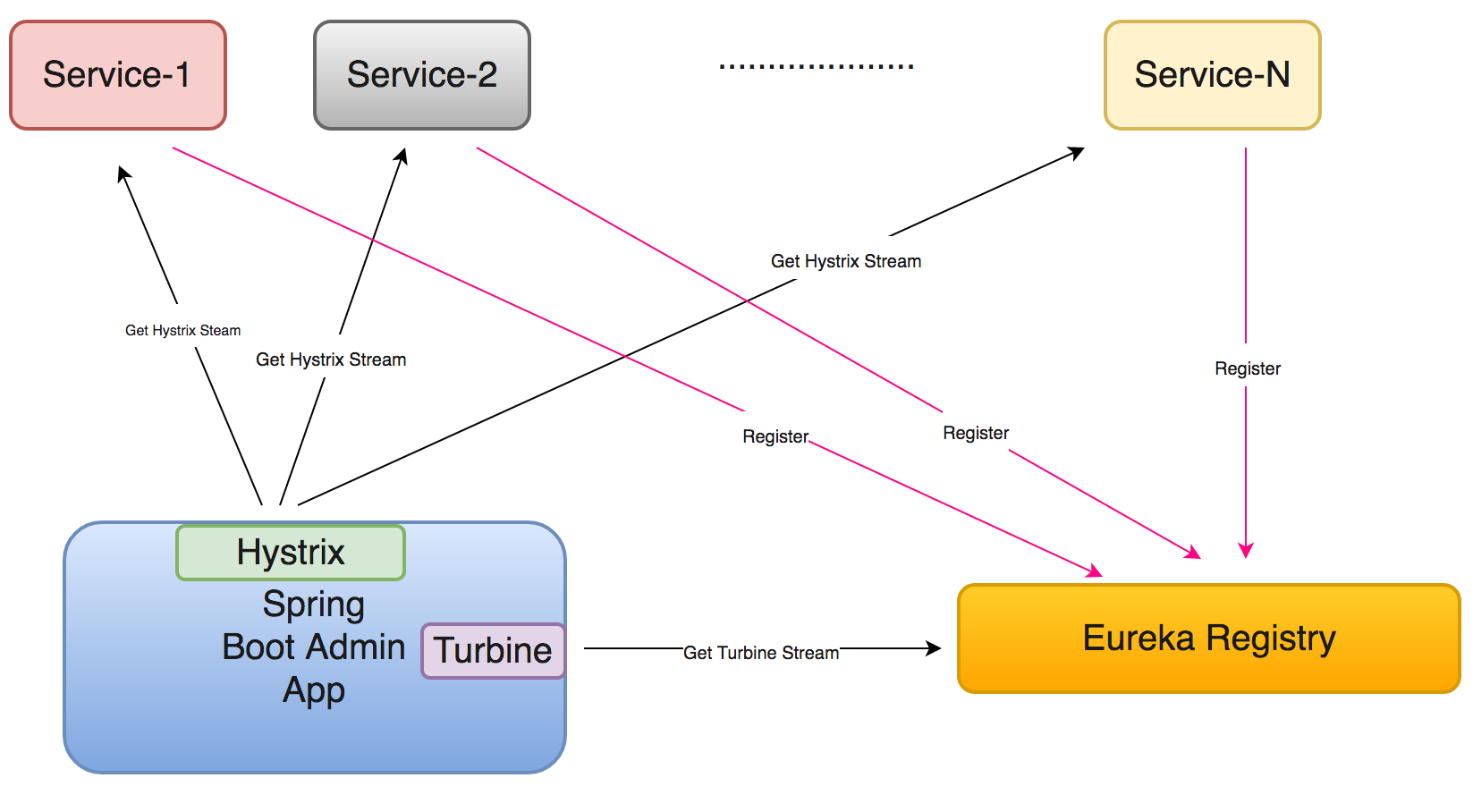
In this article, I will focus on how Spring Boot Admin can be integrated with microservices supporting Hystrix dashboard. Spring Boot Admin provides single point of access to view dashboard of all registered services individually or aggregate all dashboard into a single view using Turbine.
Once you add the Hystrix library to your micro-service, the library exposes the metrics through the ‘/hystrix.stream’ endpoint on the service.
There’s one stream per service. Clicking on the service in the spring boot admin will give you an easy access to the hystrix stream dashboard for that service.
</img>
Spring Boot Admin - Hystrix & Turbine
Turbine is another library from Netflix which helps aggregate multiple Hystrix stream and display them in a single dashboard.
In order to be able to aggregate multiple Hystrix stream, Turbine needs to be able to determine which services are currently available and where the services are. This is usually achieved by using a service discovery framework like Consul or Eureka.
Here, I am using an Eureka server. Each micro service has a Eureka client which registers with the Eureka server on startup. Turbine makes use of the instance discovery information provided by Eureka to establish connection to the microservice and read the Hystrix stream. The individual streams are passed through the Turbine aggregator so as to be able to render data in a single view.
A CHAT system essentially lets one user send messages to and receive messages from other users. The messages are usually text based but the chat system should be able to support different media types like Videos, Audio, images etc.
In the following article I will concentrate on data storage aspect of the CHAT system. I will explain the various considerations behind choosing the current date store.
Choosing A Data Store
This is what we wanted from the storage aspects of the system :
To move away from RDBMS.
Move towards a NoSQL solution with -
Flexible schema.
Horizontally scalable to meet increased load.
High performance.
Easy maintenance.
Resilient and quick recovery.
Monitoring.
RDBMS with their normalized storage structure, licensing cost and transactional, locking feature did not seem to fit into our idea of a solution with can support large DB ops/sec with minimum latency.
Flexible schema helps with evolving requirements and new features. Data store maintenence like backup, restore , scaling up etc. should not be a ton of work.
What We Choose:
</img>
MongoDB Atlas - A software-as-a-solution version of the well known popular document based NoSQL database.
Why We Choose MongoDB Atlas:
Hosted service. No upfront investment in hardwares or need to have a NoSQL DB Administrator to setup the cluster.
Document based storage with support for social media features like tags, likes, comments etc.
Ability to easily scale up or across by either increasing the machine configuration or by adding additional shards.
Data locality supports fast data retrival and storage.
Automated backup, data snapshotting and one click restore.
High availability with automated failover and recovery.
Automated minor version upgrade of the MonogDB cluster.
One click upgrade for major versions.
Dashboards visually representing various system and database level metrics. These metrics are archived to provide a historical overview.
Alerting based on system and database level metrics.
Alerting integration with other third part tools like SLACK and Pagerduty.
Access to MongoDB enterprise support.
Cluster security using TLS/SSL Encryption, authentication, authorization, IP whitelisting etc.
Microservice architecture brings in a lot flexibility with application development and deployment but introduces a new level complexity when it comes to handling transactions and inter-service communication.
The whole microservices architecture is like a huge web consisting of several services each talking to one or more of other services.
</img>
News feed events aggregation service
Each service has its own performance and reliability as Service Level Agreement (SLA) which in turn may be affected by the performance of a dependent services.
A front facing service could be held hostage if one or more of services it is dependent are unable to meet their SLA’s. This in turn would impact the SLA of the service and could end up providing a bad user experience for the users of the service.
It’s not just one API call or one user that we are talking about, it could be most it not all of the API calls that are coming to the service for different users.
</img>
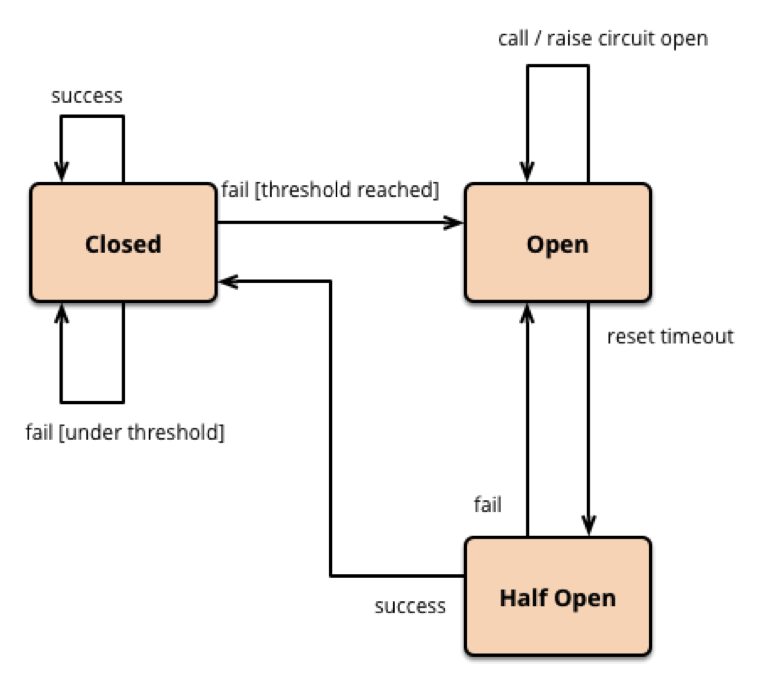
This is where the ‘Circuit Breaker’ design pattern comes into picture. The design pattern is similar to how an electrical circuit breaker works. The idea is to trip the circuit when when something bad happens thus preventing the issue from escalating and turning into a disaster.
The below diagram illustrates the design pattern as explained by ‘Martin Fowler’ in ‘Application Architecture’.
</img>
Key Parameters Affecting API SLAs in a MicroService Architecture:
Connection Timeouts
Happens when the client is unable to connect to a service within a given timeframe. This may be caused due to a slow or unresponsive service.
Read Timeouts
When the client is unable to read the results from the service within a given timeframe. The service may be doing a lot of computation or is using some inefficient way to prepare data to be returned.
Exception Caused Due To
Bad data sent to the service by the client
Service being down
Issue on the service
Issue on the client while parsing the response. Response change on the service and the client unaware of it.
Building Resilient Service
Netflix has built Hystrix, a library which implements the circuit breaker pattern. This library will help us build resilient services.
Key advantages of Circuit Breaker Pattern:
Fail fast and rapid recovery.
Prevent cascading failure.
Fallback and gracefully degrade when possible.
Hystrix library:
Implements the circuit breaker pattern.
Provides near real time monitoring via. Hystrix stream and Hystrix dashboard.
Generates monitoring events which can be published to external systems like Graphite.
Use Case: NewsFeed Aggregation Service
Overview:
NewsFeed Aggregation service is responsible to deliver data which will be used to render the ‘Recent Activities’ section of the page for an user. Recent activities is similar to facebook timeline which contains any updates/notification/activities that happened between the time the user was last on the site and now.
</img>
News feed events aggregation service
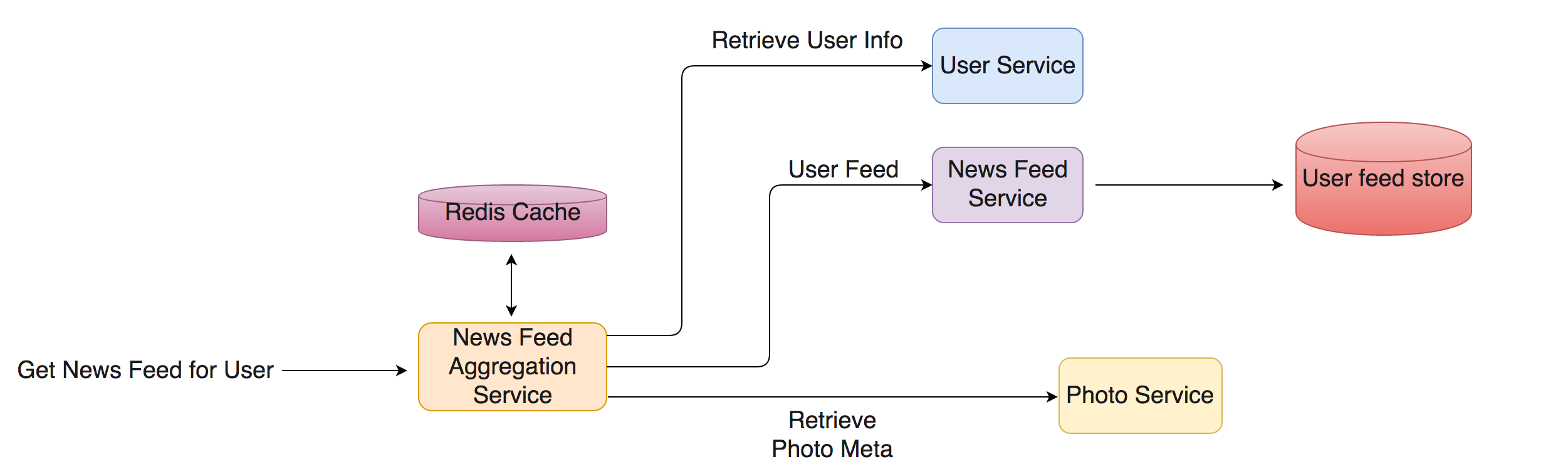
The aggregation service is dependent on 3 other microservices. News Feed service being the primary source of feed whose data is further enriched based on the information retrieved from user-service and photo-service.
The feed is shown on the landing page of the application and acts as a driver for user engagement on the site. Hence, it is of utmost importance that the operation to fetch the required new feed data is fast and reliable.
We neither want the user to see a long ‘loading…’ animation or see no data at all since. The backend services need to be highly resilient.
Application Flow Diagram: Before Integrating With Hystrix
Here’s a flow diagram indicating how the user feed is fetched and enriched. The Newsfeed Aggregation service has three clients, each talking to different services (news feed, user and photo service).
</img>
Application flow without Hystrix
Each client has a certain ‘Read Time Out’ and ‘Connect Time Out’ associated with it.
Let’s assume these are configured to be 3 seconds each. So, if dependent services don’t respond back in 3s or if the calling service is unable to establish a connection within 3 seconds, a read or connect timeout exception is thrown by the client.
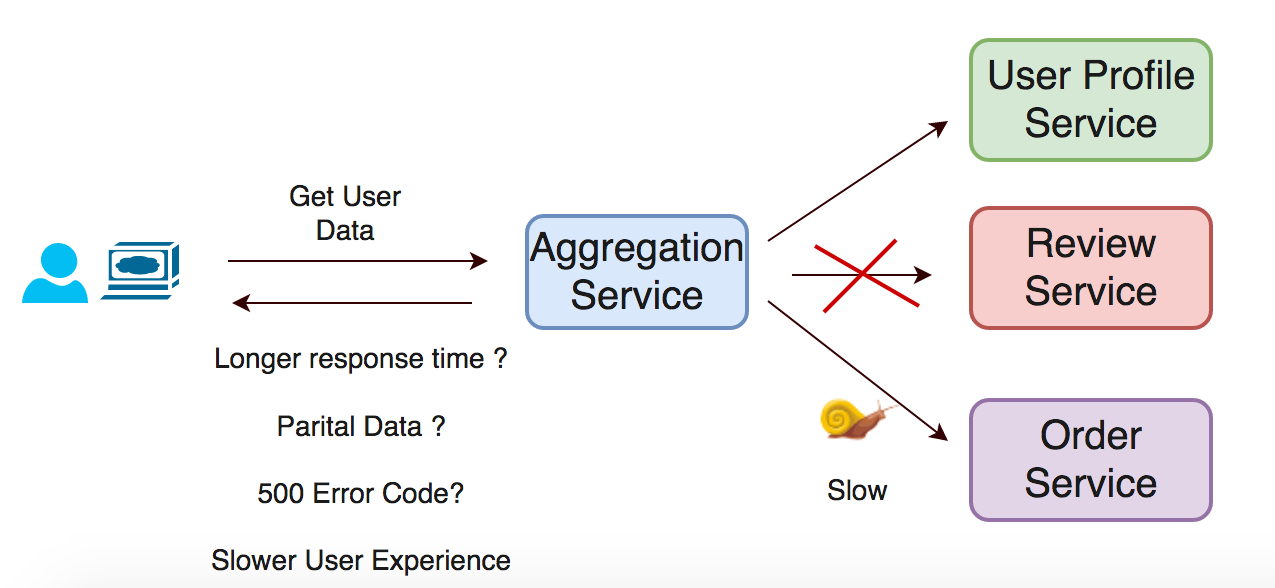
In the happy path scenario, everything will work as usual and the dependent service will return data within some miliseconds. The application is able to retrieve the feed and return it to the user.
However, if one of the dependent services go down then every user will see at least a 3 seconds increase in the response time to return partial data or no data at all. The page will be slower and user experience not so good.
Application Flow Diagram: After Integrating With Hystrix
</img>
Application flow without Hystrix integrated
Using the Hystrix library, we can have the service execute a fallback operation when a certain threshold of failure rate for talking to an external service is reached. This is essentially a state where the circuit is considered open. As soon as the circuit is open, the service only executes the fallback operation and avoids reaching out to the external service for a certain cooldown period. Thus, saving the expensive 3 second timeout period for each API call to the external service.
After the cool down period, Hystrix will allow one request to go out to the external service, if this succeeds then the circuit will be closed again and all subsequent calls will reach out to the external service until the threshold for failure is reached next time.
If you are a Java developer working on MicroServices then its highly probable that you will be dealing with older services which are written on
JDK 1.7 or older with Maven 2.x and newer services written in JDK 1.8 and Maven 3.x.
In order to work on both the newer and older services, you would need to have all of Maven 2.x, Maven 3.x , JDK 1.8, JDK 1.7 installed on
you OSX.
Even though you have multiple versions installed, you system environment variables can point to only one of the version.
However, you can use the following script to easily switch between different version on same of different terminal window.
 </img>
</img>
 </img>
</img>
 </img>
</img>
 </img>
</img>
 </img>
</img>
 </img>
</img>
 </img>
</img>
 </img>
</img>
 </img>
</img>
 </img>
</img>